Unlocking AI’s Potential: The Critical Role of Synthetic Data Quality
In the age of AI dominance, one thing is clear: data is the lifeblood of innovation. But not just any data will do. The quality of data—particularly synthetic data—is the backbone of accurate, reliable, and scalable AI systems. Here’s why synthetic data is reshaping the AI landscape and how quality drives its success.
Why Data Quality Matters in AI
AI systems thrive on vast datasets, but real-world data often falls short. It's messy, incomplete, or riddled with biases that compromise model performance. Enter synthetic data: a powerful alternative that mirrors real-world scenarios without the baggage. By generating perfectly labeled, bias-controlled datasets, synthetic data ensures AI systems are trained on consistent, diverse, and ethically sound inputs.
The Hidden Cost of Poor Data
Imagine building a self-driving car with a blindfold on—it’s a disaster waiting to happen. Poor-quality data can mislead AI, resulting in inaccuracies, biased decisions, and costly errors. For enterprises, this translates to lost revenue, reputational damage, and regulatory penalties. Synthetic data, when done right, mitigates these risks by offering precision, control, and scalability.
Synthetic Data: The Gold Standard
Synthetic data isn't just a workaround; it’s a game-changer. Unlike real-world data, which may require complex permissions or expose sensitive information, synthetic data offers a risk-free, privacy-preserving solution. Generated by algorithms, it recreates diverse scenarios, enabling AI systems to train in conditions they might rarely—or never—encounter in the wild.
Consider the healthcare sector. Real patient data is tightly regulated, making access a challenge. Synthetic data can replicate this information while safeguarding privacy, empowering researchers to innovate without constraints. Similarly, autonomous vehicles can train on millions of synthetic driving scenarios—nighttime conditions, snowstorms, or sudden obstacles—without endangering lives.
Keys to High-Quality Synthetic Data
While synthetic data offers enormous potential, its value hinges on quality. Here's what sets high-quality synthetic data apart:
Realism: It must closely mimic real-world patterns to avoid introducing errors.
Diversity: Capturing varied scenarios ensures AI systems perform well across contexts.
Bias Control: Synthetic data eliminates human biases, promoting fairness and ethical AI.
Scalability: Generating datasets at scale must not sacrifice fidelity.
Without these attributes, synthetic data risks amplifying the very problems it seeks to solve.
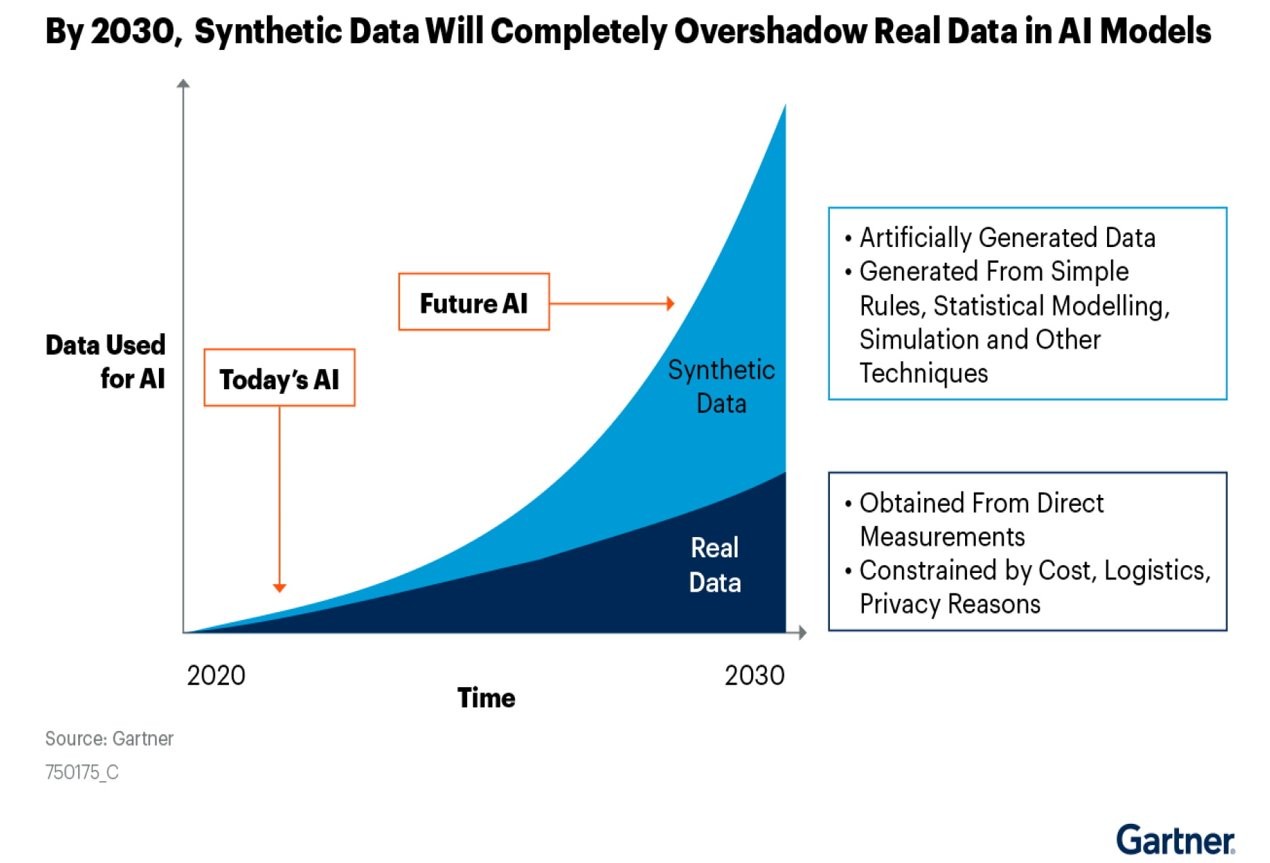
The Future is Synthetic
The AI revolution is just beginning, and synthetic data is paving the way for its next breakthroughs. From training chatbots to powering autonomous systems, industries across the board are embracing synthetic data for its efficiency, reliability, and limitless possibilities.
At Syntree, we specialize in creating high-quality synthetic data tailored to your AI needs. Whether you’re building next-gen healthcare models or cutting-edge financial tools, our synthetic data solutions deliver accuracy and scalability you can trust. Let’s shape the future of AI—together.
Ready to explore the power of synthetic data? Join the Syntree network today and start exploring our datasets.
Article by

Paul Tomkinson
Contributor
Published on
Dec 2, 2024