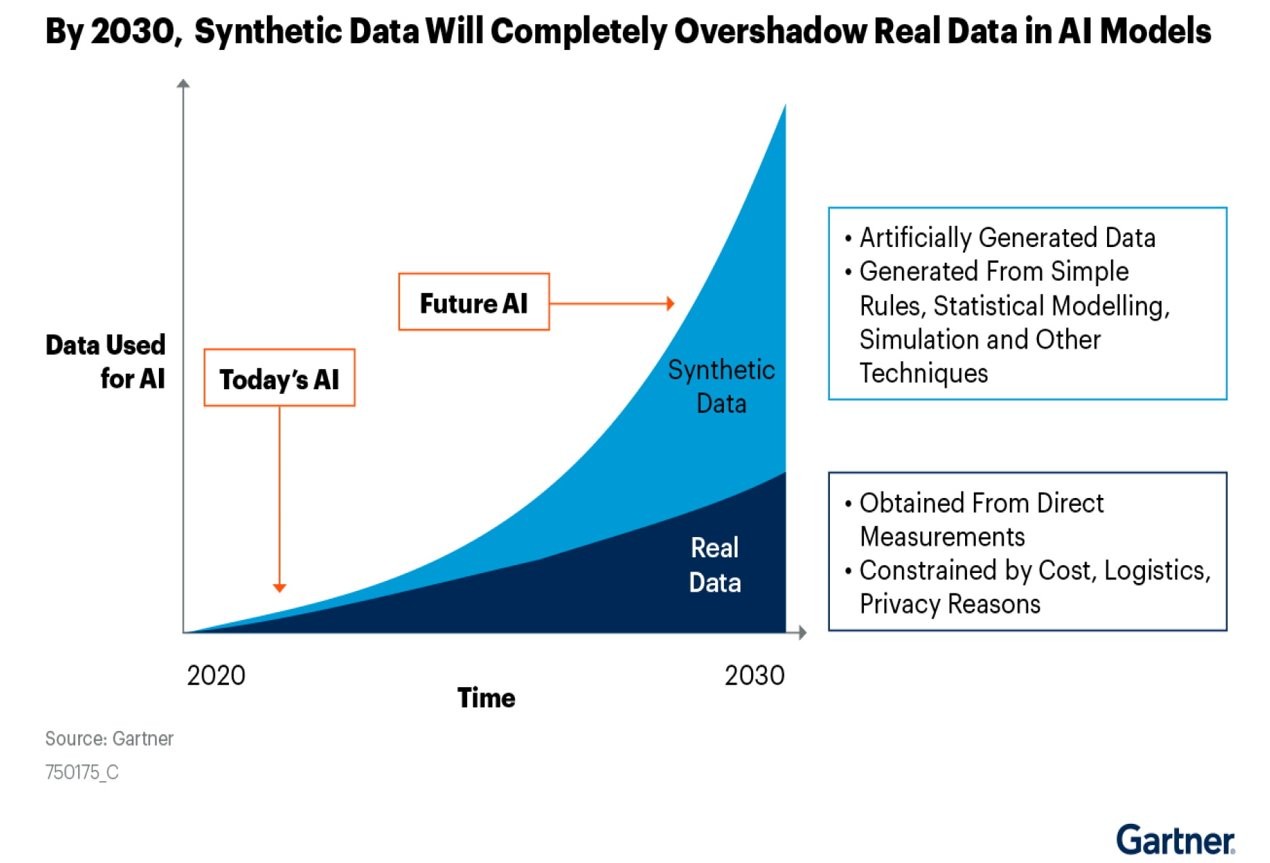
The Rise of Synthetic Data: Unlocking AI's Next Frontier
In the rapidly evolving field of artificial intelligence (AI), synthetic data is emerging as a transformative force. Synthetic data refers to data that is artificially generated rather than collected from real-world events. This data can take many forms, from text and images to tabular datasets or even fully simulated environments. Its creation involves advanced algorithms and models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and rule-based simulations. These tools produce data that mimics real-world patterns while preserving privacy and security by avoiding the use of sensitive, personal information.
Synthetic data has become indispensable in AI for several reasons. First, it allows researchers and developers to overcome the bottleneck of limited real-world data, especially in specialized domains like healthcare or autonomous driving. For instance, generating diverse datasets of rare diseases or simulating millions of driving scenarios can dramatically improve AI model robustness. Second, synthetic data enables the creation of balanced datasets, addressing issues like bias and imbalance present in natural data. Finally, by circumventing regulatory restrictions associated with handling sensitive data, synthetic data facilitates seamless development across industries.
The generation of synthetic data is a sophisticated process. Techniques like GANs pit two neural networks against each other—one generating data and the other evaluating its realism. VAEs, on the other hand, encode data into a latent space and decode it back into a synthetic representation. Procedural simulations use predefined rules and physics engines to create hyper-realistic scenarios for domains such as gaming or robotics. These methods are evolving rapidly, enabling the generation of highly realistic datasets that were once thought impossible.
Synthetic Data as the Cornerstone of AI's Future
The role of synthetic data in advancing frontier AI models is not just transformative but foundational. As AI scales to tackle increasingly complex tasks—such as building large language models like GPT-4 or multi-modal systems like DALL-E—the demand for diverse, high-quality, and ethically sourced data is skyrocketing. Real-world data collection is expensive, time-consuming, and often laden with ethical constraints. Synthetic data bridges this gap, enabling scalable and ethical AI development.
Cutting-Edge Techniques in Synthetic Data Generation
Recent research has pushed the boundaries of what synthetic data can achieve. A 2023 paper by NVIDIA and Stanford University highlighted the use of Diffusion Models for generating synthetic data at scale. Diffusion models iteratively refine noise to produce high-resolution, realistic outputs, offering an alternative to GANs with improved stability and diversity. Additionally, Neural Radiance Fields (NeRFs) have emerged as a powerful technique for creating 3D synthetic environments, which are critical for training autonomous systems.
Another breakthrough is the integration of synthetic pre-training for foundation models. Research from OpenAI demonstrated how synthetic text data generated by smaller language models can be used to pre-train larger models, effectively bootstrapping performance in domains with limited natural data. Similarly, in computer vision, researchers at MIT have used photorealistic synthetic datasets to train object detection models, showing that synthetic data can outperform real-world data when curated for specific tasks.
Applications in Frontier Model Development
Synthetic data is already proving essential in developing specialized AI systems. For example, in healthcare, synthetic data enables models to train on realistic patient data without violating privacy laws. Research from the Mayo Clinic showcased synthetic patient records generated via GANs that maintained statistical fidelity while preserving anonymity, opening doors for AI in diagnostics and treatment planning.
In autonomous driving, companies like Waymo and Tesla rely heavily on synthetic environments to simulate rare edge cases—such as erratic pedestrian behavior or extreme weather conditions—that are difficult to capture in real-world datasets. Similarly, synthetic data has powered breakthroughs in robotics, where procedural generation of environments has enabled agents to learn tasks faster and more efficiently.
Beyond Training: Synthetic Data in Testing and Deployment
Synthetic data is not limited to model training; it plays a pivotal role in testing and deployment. Researchers at ETH Zurich recently developed frameworks for synthetic stress testing, where AI models are evaluated against edge cases generated specifically to probe weaknesses. This approach ensures robustness in real-world applications, especially in safety-critical industries like aviation and finance.
Moreover, synthetic data is central to fine-tuning and personalization of models. Emerging techniques, such as prompt engineering with synthetic data, allow models like GPT to adapt to niche applications by generating synthetic examples tailored to specific prompts. This is particularly useful in domains like legal and scientific research, where labeled datasets are scarce. In the past year, synthetic data generation has achieved remarkable progress, offering innovative solutions across various domains.
Here are five significant advancements from 2024:
Enhancing Data Quality with Synthetic Data: Researchers have emphasized the importance of data quality over quantity. Synthetic data has been identified as a powerful tool to improve data quality, enabling researchers to construct datasets that meet exact information needs, thereby enhancing model efficiency and performance. Business Insider
Synthetic Data in Medical Imaging: Generative Adversarial Networks (GANs) have been applied to medical imaging, creating realistic synthetic images that improve segmentation accuracy, image quality, and multimodal analysis. This advancement addresses the scarcity of annotated medical data and enhances AI model performance in healthcare applications. MDPI
Synthetic Data for Face Recognition: The Face Recognition Challenge at CVPR 2024 focused on using synthetic data to train face recognition systems. Participants explored novel face generative methods, contributing to advancements in addressing data privacy concerns, demographic biases, and performance in challenging scenarios like aging and occlusions. ArXiv
Addressing Model Collapse in AI Training: Research has identified the risk of "model collapse," where AI models degrade when trained on recursively generated synthetic data. Studies have proposed mitigation strategies, such as embedding watermarks in AI-generated content and combining synthetic data with human-generated data to maintain model integrity. Financial Times
Synthetic Data in Fraud Detection and Confidentiality Systems: Synthetic data has been utilized to test and train fraud detection and confidentiality systems. By creating realistic data representations, these systems can recognize and react to various situations, enhancing their effectiveness in identifying intrusions and protecting sensitive information. Wikipedia
These advancements highlight the growing importance of synthetic data in advancing AI while addressing challenges related to data availability, privacy, and model robustness.
The Cutting Edge: A Unified Framework for Synthetic Data
The future of synthetic data lies in unified synthetic ecosystems. Platforms that integrate data generation, validation, and deployment pipelines are emerging as the next frontier. OpenAI and Google Research have both highlighted the potential of combining synthetic data with active learning—where models actively request the generation of new synthetic samples to improve their weakest areas.
Another exciting avenue is the convergence of synthetic data with federated learning. A 2024 study from DeepMind demonstrated how synthetic data could be used to simulate decentralized datasets, allowing AI to train across distributed environments without sharing sensitive user data.
Conclusion: A Catalyst for AI’s Ethical and Scalable Future
Synthetic data is more than a technological innovation; it is a paradigm shift. As AI moves toward solving increasingly complex global challenges, the ability to generate diverse, high-fidelity datasets ethically and at scale will be indispensable. From healthcare to autonomous systems, from pre-training to stress testing, synthetic data is revolutionizing how we build and deploy AI. By embracing cutting-edge research and techniques, synthetic data is not just keeping pace with AI—it is defining its future.
Article by

Paul Tomkinson
Contributor
Published on
Oct 11, 2024